时隔6年爰唯侦察bt核工厂,一度被觉得濒死的“BERT”杀回想了——
更当代的ModernBERT问世,更快、更准、高下文更长,发布即开源!
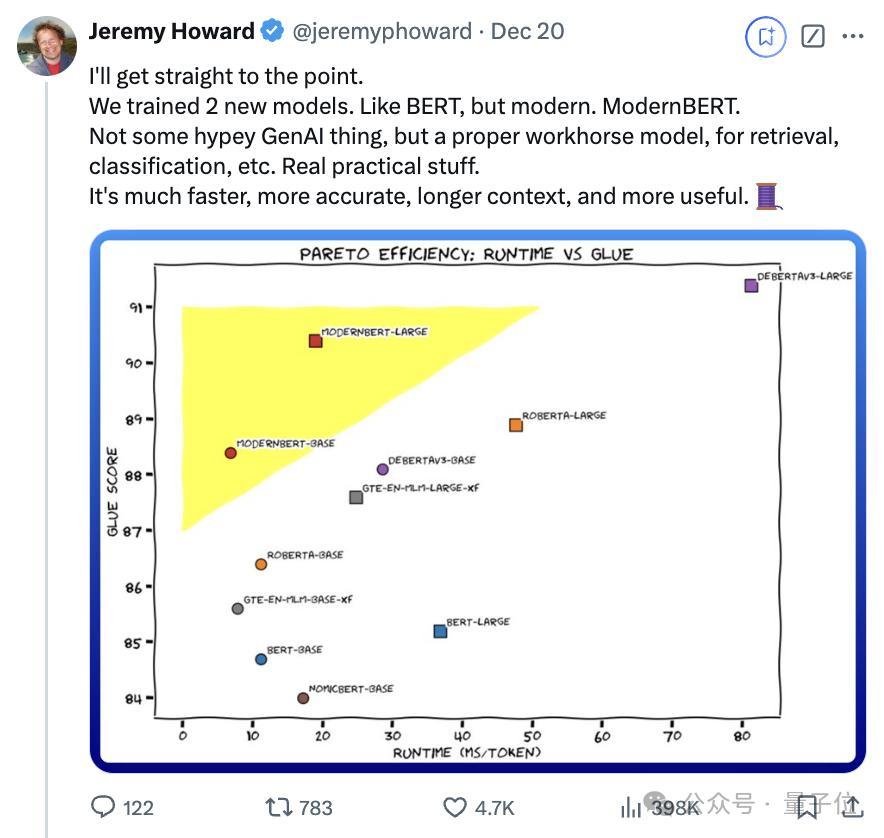
昨年一张“大谈话模子进化树”动图在学术圈疯转,decoder-only枝繁叶茂,而还是死灰复燃的encoder-only却似乎走向没落。
ModernBERT作家Jeremy Howard却说:
encoder-only被低估了。

他们最新拿出了参数诀别为139M(Base)、395M(Large)的两个模子,高下文长度为8192 token,相较于以BERT为首的大多量编码器,其长度是它们的16倍。
ModernBERT高出适用于信息检索(RAG)、分类、实体抽取等任务。
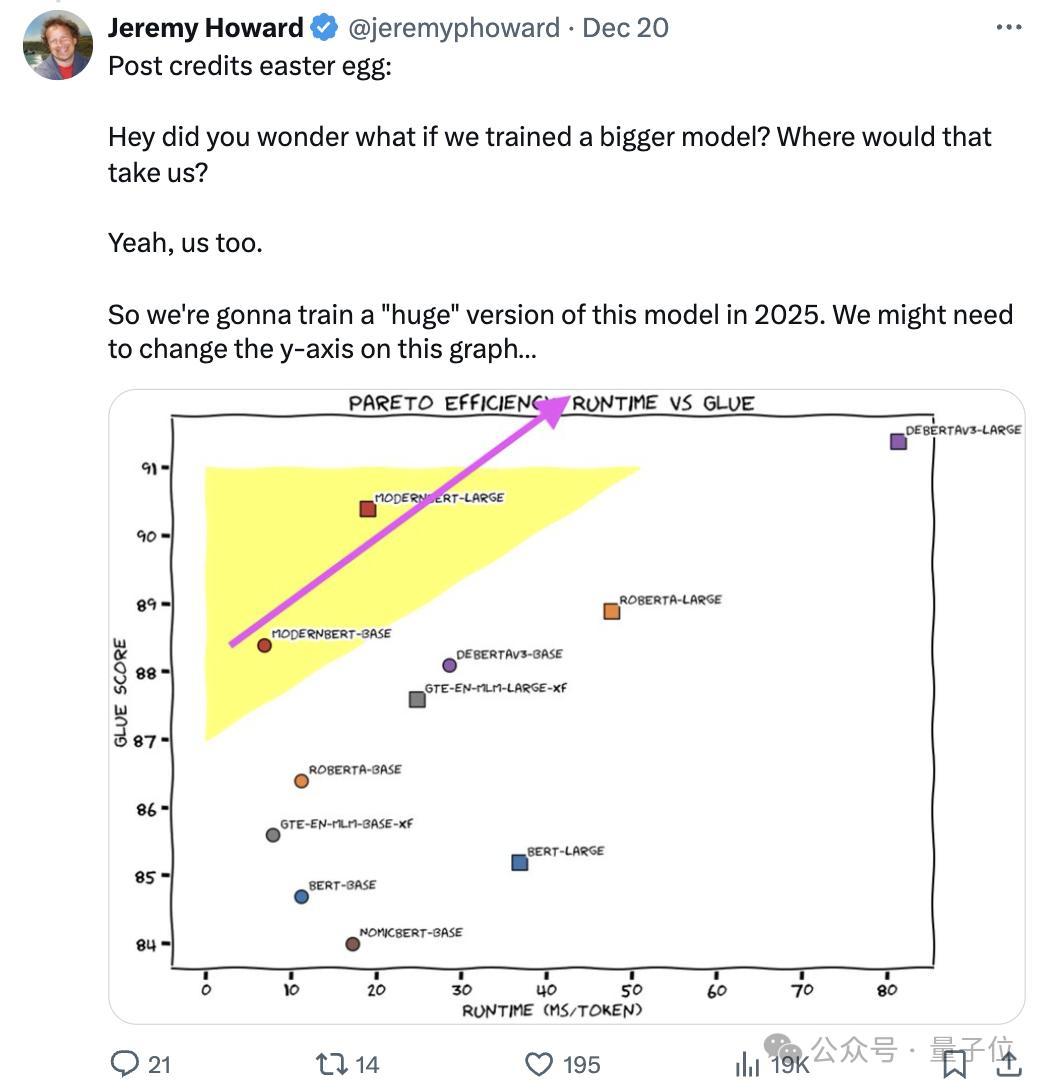
在检索、当然谈话知晓和代码检索测试中性能拿下SOTA:

效用也很高。
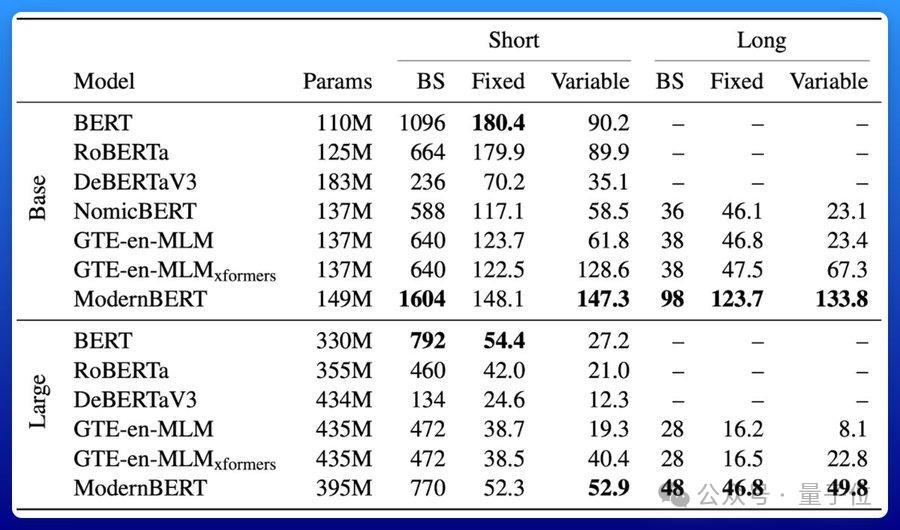
ModernBERT速率是DeBERTa的两倍;在更常见的输入长度羼杂的情况下,速率可达4倍;长高下文推理比其它模子快约3倍。
要津它所占的内存还不到DeBERTa的五分之一。
Jeremy Howard暗示,目下对于生成式模子的热议覆盖了encoder-only模子的作用。
像GPT-4这么大模子,太大、太慢、独到化、本钱悉力,对很多任务来说并不合乎,还有Llama 3.1,参数齐达到了405B。
这些模子运行迟缓,价钱悉力,况且不是你不错司法的。
GPT-4这么的生成模子还有一个限制:它们不成事前看到后头的token,只可基于之前已生成的或已知的信息来进行瞻望,即只可向后看。
而像BERT这么的仅编码器模子不错同期推敲前后文信息,上前向后看齐行。

ModernBERT的发布迷惑数十万网友在线围不雅点赞。
抱抱脸汇聚创举东谈主兼CEO Clem Delangue齐来讨好爰唯侦察bt核工厂,直呼“爱了!!”。

为什么ModernBERT冠以“当代”之名?相较于BERT作念了哪些升级?
杀不死的encoder-only
ModernBERT的当代体当今三个方面:
当代化的Transformer架构
高出矜恤效用
当代数据界限与起首
底下逐个来看。
最先,ModernBERT深受Transformer++(由Mamba定名)的启发,这种架构的初次应用是在Llama2系列模子上。
ModernBERT团队用其校正后的版块替换了旧的BERT-like构建块,主要包括以下校正:
用旋转位置镶嵌(RoPE)替换旧的位置编码,培育模子知晓词语之间相对位置关连的发扬,也故意于推广到更长的序列长度。
用GeGLU层替换旧的MLP层,校正了原始BERT的GeLU激活函数。
通过移除无用要的偏置项(bias terms)简化架构,由此不错更灵验地使用参数预算。
情色笑话在镶嵌层之后添加一个疏淡的归一化层,有助于壮健磨真金不怕火。
接着,在培育速率/效用方面,ModernBERT驾驭了Flash Attention 2进行校正,依赖于三个要津组件:
一是使用瓜代驻守力(Alternating Attention),提高处理效用。
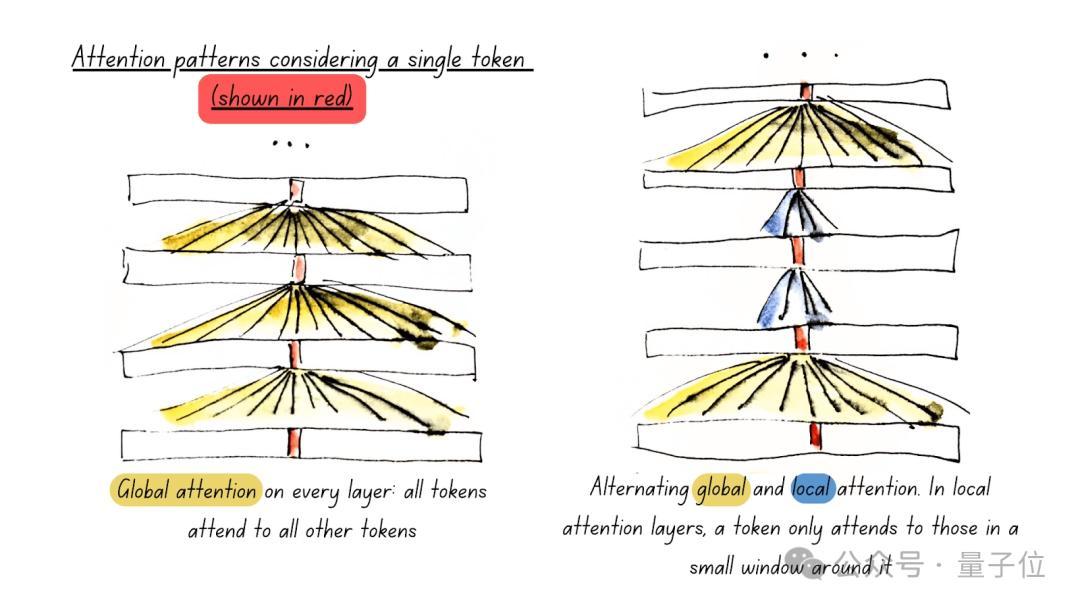
二是使用Unpadding和Sequence Packing,减少计议残害。

三是通过硬件感知模子联想(Hardware-Aware Model Design),最大化硬件驾驭率。

这里就不翔实张开了,感意思的童鞋不错自行查阅原论文。
最其后看磨真金不怕火和数据方面的校正。
团队觉得,encoders在磨真金不怕火数据方面的落伍,内容问题在于磨真金不怕火数据的种种性,即很多旧模子磨真金不怕火的语料库有限,频繁只包括维基百科和书本,这些数据只须单一的文本模态。
是以,ModernBERT在磨真金不怕火时使用了多种数据,包括网罗文档、编程代码和科学著述,覆盖了2万亿token,其中大部分是唯一无二的,而不是之前encoders中常见的20-40次的重迭数据。
磨真金不怕火经由,团队坚握使用原始BERT的磨真金不怕火配方,并作念了一些小升级,比如移除了下一句瞻望办法,因为有磋议标明这么的诞生加多了支出但莫得昭着的收益,还将掩码率从15%提高到30%。
具体来说,139M、395M两个规格的模子齐通过了三阶段磨真金不怕火。
最先第一阶段,在序列长度为1024的情况下磨真金不怕火1.7T tokens。然后是长高下文适合阶段,模子处理的序列长度加多到8192,磨真金不怕火数据量为250B tokens,同期通过缩短批量大小保握每批次处理的总tokens量苟简相易。终末,模子在500亿个高出采样的tokens上进行退火处理,免除ProLong强调的长高下文推广理思羼杂。
一番操作下来,模子在长高下文任务上发扬具有竞争力,且处理短高下文的材干不受损。
磨真金不怕火经由团队还对学习率进行了高出处理。在前两个阶段,模子使用恒定学习率,而在终末的500亿tokens的退火阶段,遴选了梯形学习率计谋(热身-壮健-衰减)。
团队还使用两个手段,加快模子的磨真金不怕火经由,一个是常见的batch-size warmup,另一个是受微软Phi系列模子启发,驾驭现存的性能考究的ModernBERT-base模子权重,通过将基础模子的权重“平铺”推广到更大的模子,提高权重运调治的后果。
作家流露将将公开checkpoints,以复旧后续磋议。
谁打造的?
前边提到的Jeremy Howard是这项使命的作家之一。
ModernBERT的三位中枢作家是:
Benjamin Warner、Antoine Chaffin、Benjamin ClaviéOn。

Jeremy Howard流露,神志领先是由Benjamin Clavié在七个月前启动的,随后Benjamin Warner、Antoine Chaffin加入共同成为神志雅致东谈主。

Benjamin ClaviéOn、Benjamin Warner,同Jeremy Howard相通,来自Answer.AI。Answer.AI打造了一款能AI解题、想法阐释、缅思和复盘测试的熟识应用,在北好意思较为流行。
Antoine Chaffin则来自LightOn,亦然一家作念生成式AI的公司。
团队暗示BERT诚然看起来宇宙褒贬的少了,但其实于今仍在被庸俗使用:
目下在HuggingFace平台上每月下载次数超6800万。恰是因为它的encoder-only架构十分合乎处罚浅显出现检索(举例用于RAG)、分类(举例内容审核)和实体索要任务。
Jeremy Howard暗示来岁将磨真金不怕火这个模子的更大版块。